数据结构基础知识
学习数据结构首先从认识以下几个概念开始。
1.数据
数据是指所有能输入到计算机中的描述客观事物的符号,包括文本、声音、图像、符号等。我们经常使用的“扫一扫”的二维码,也是数据。
2.数据元素
数据元素是数据的基本单位,也称节点或记录,如图1-1所示。
图1-1 数据元素(略)
3.数据项
数据项表示有独立含义的数据最小单位,也称域。若干个数据项构成一个数据元素,数据项是不可分割的最小单位,如图1-1所示的“86”。
4.数据对象
数据对象是指相同特性的数据元素的集合,是数据的一个子集。
5.数据结构
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。
数据结构是带“结构”的数据元素的集合,“结构”是指数据元素之间存在的关系。数据结构研究的问题是将带有关系的数据存储在计算机中,并进行相关操作。数据结构包含逻辑结构、存储结构和运算三个要素。
6.逻辑结构和存储结构
逻辑结构是数据元素之间的关系,存储结构是数据元素及其关系在计算机中的存储方式。例如,小明和小勇是表兄弟,这是他们之间的逻辑关系;他们在教室里面的位置是他们的存储结构。无论他们的座位怎样安排,是挨着坐,还是分开坐,都不影响他们的表兄弟关系。
逻辑结构:数据元素间抽象化的相互关系,与数据的存储无关,独立于计算机,它是从具体问题中抽象出来的数学模型。
数据结构的逻辑结构共有以下4种。
(1)集合——数据元素间除“同属于一个集合”外,无其他关系。
集合中的元素是离散、无序的,就像鸡圈中的小鸡一样,可以随意走动,它们之间没有什么关系,唯一的亲密关系就是在同一个鸡圈里,如图1-2所示。数据结构重点研究的是数据之间的关系,而集合中的元素是离散的,没有什么关系。因此,集合虽然是一种数据结构,但在数据结构书中不讲,在离散数学的集合论部分有重点讲述。
图1-2 (略)
(2)线性结构——一个对一个,如线性表、栈、队列、数组、广义表。
线性结构就像穿珠子,是一条线,不会分叉,如图1-3所示。有唯一的开始和唯一的结束,除了第一个元素外,每个元素都有唯一的直接前驱(前面那个);除了最后一个元素外,每个元素都有唯一的直接后继(后面那个)。
图1-3 线性结构(略)
(3)树形结构——一个对多个,如树。
树形结构就像一棵倒立的树,树根可以发出多个分支,每个每支也可以继续发出分支,树枝和树枝之间是不相交的,如图1-4所示。
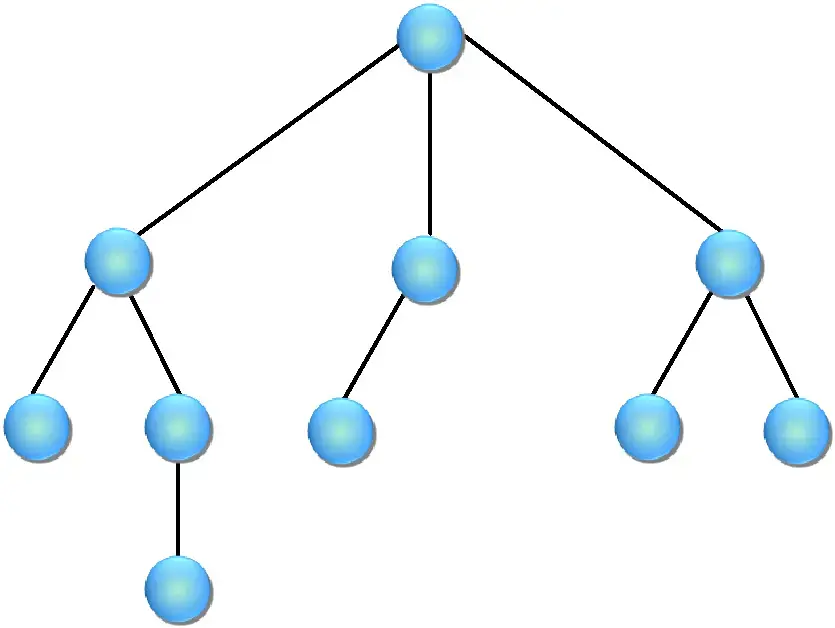

图1-4 树形结构
(4)图形结构——多个对多个,如图、网。
图形结构就像我们经常见到的地图,任何一个节点都可能和其他节点有关系,就像一张错综复杂的网,如图1-5所示。
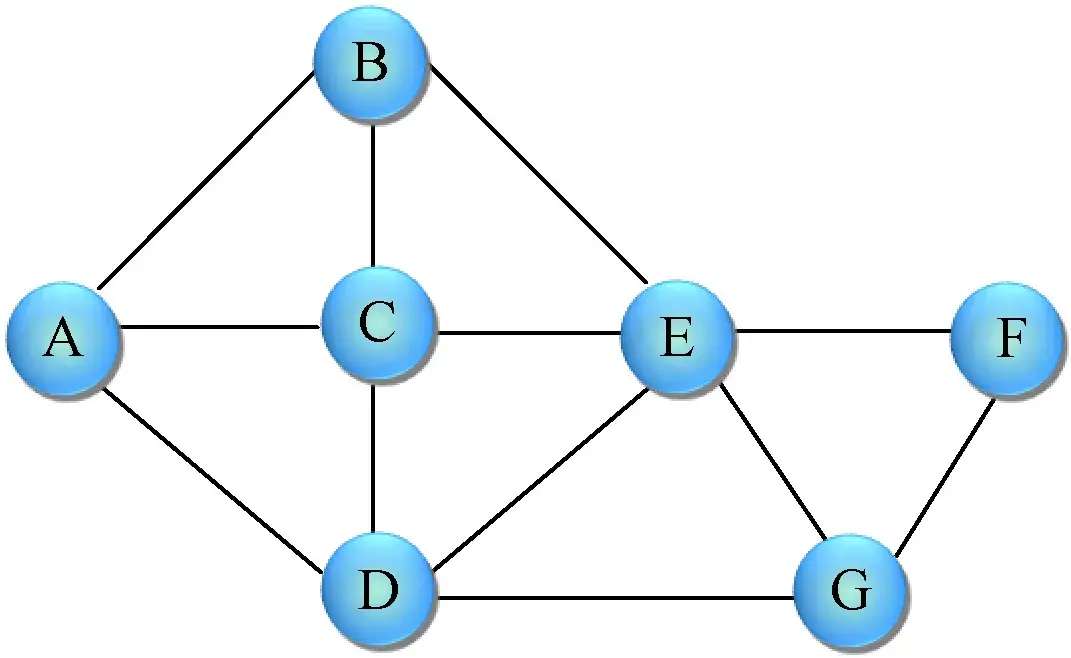
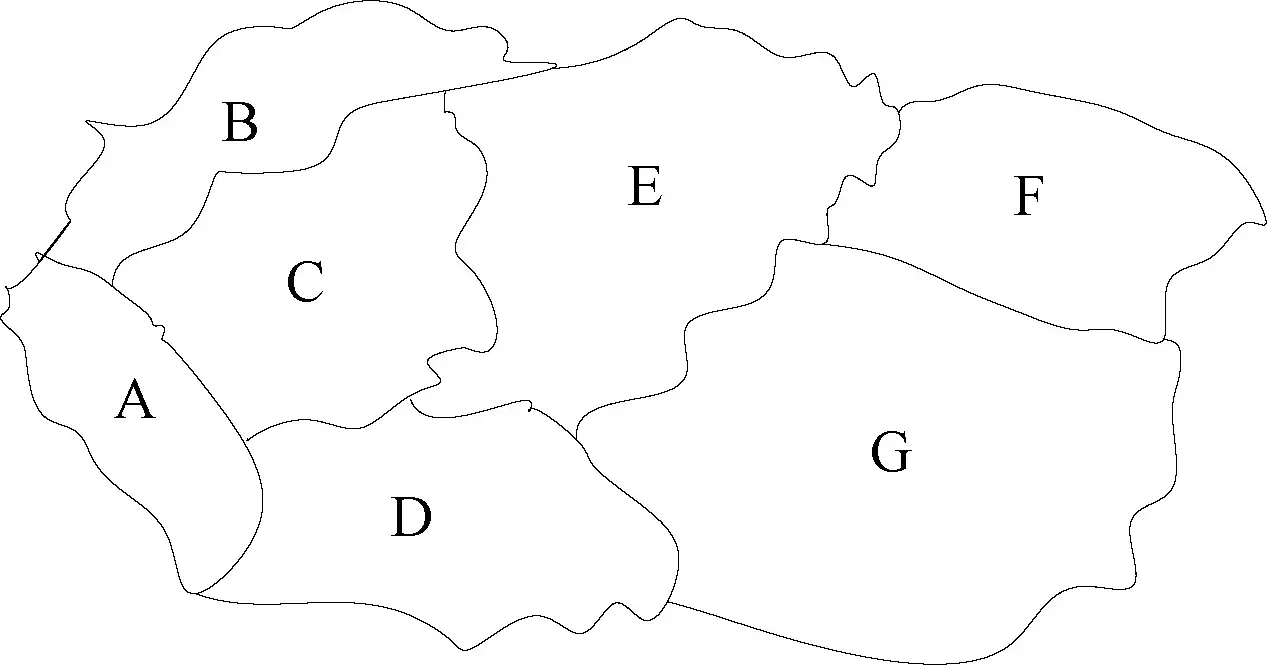
图1-5 图形结构
存储结构:数据元素及其关系在计算机中的存储方式。
存储结构可以分为4种:顺序存储、链式存储、散列存储和索引存储。很多数据结构类书籍只介绍了前两种基本的存储结构,这里加上后两种,以便读者了解。
(1)顺序存储
顺序存储是指逻辑上相邻的元素在计算机内的存储位置也是相邻的。例如,张小明是哥哥,张小波是弟弟,他们的逻辑关系是兄弟,如果他们住的房子是前后院,也是相邻的,就可以说他们是顺序存储,如图1-6所示。
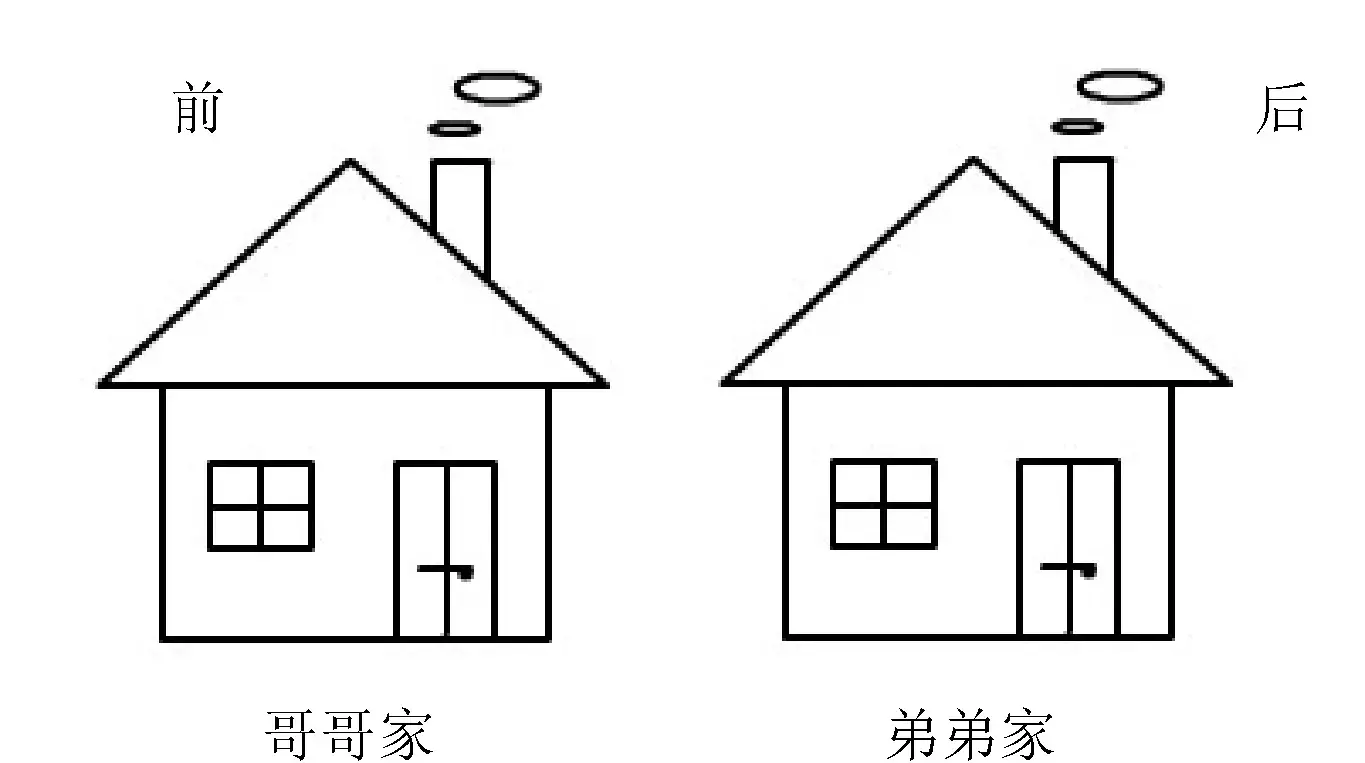
图1-6 兄弟两家前后相邻
顺序存储采用一段连续的存储空间,将逻辑上相邻的元素存储在连续的空间内,中间不允许有空。顺序存储可以快速定位第几个元素的地址,但是插入和删除时需要移动大量元素,如图1-7所示。
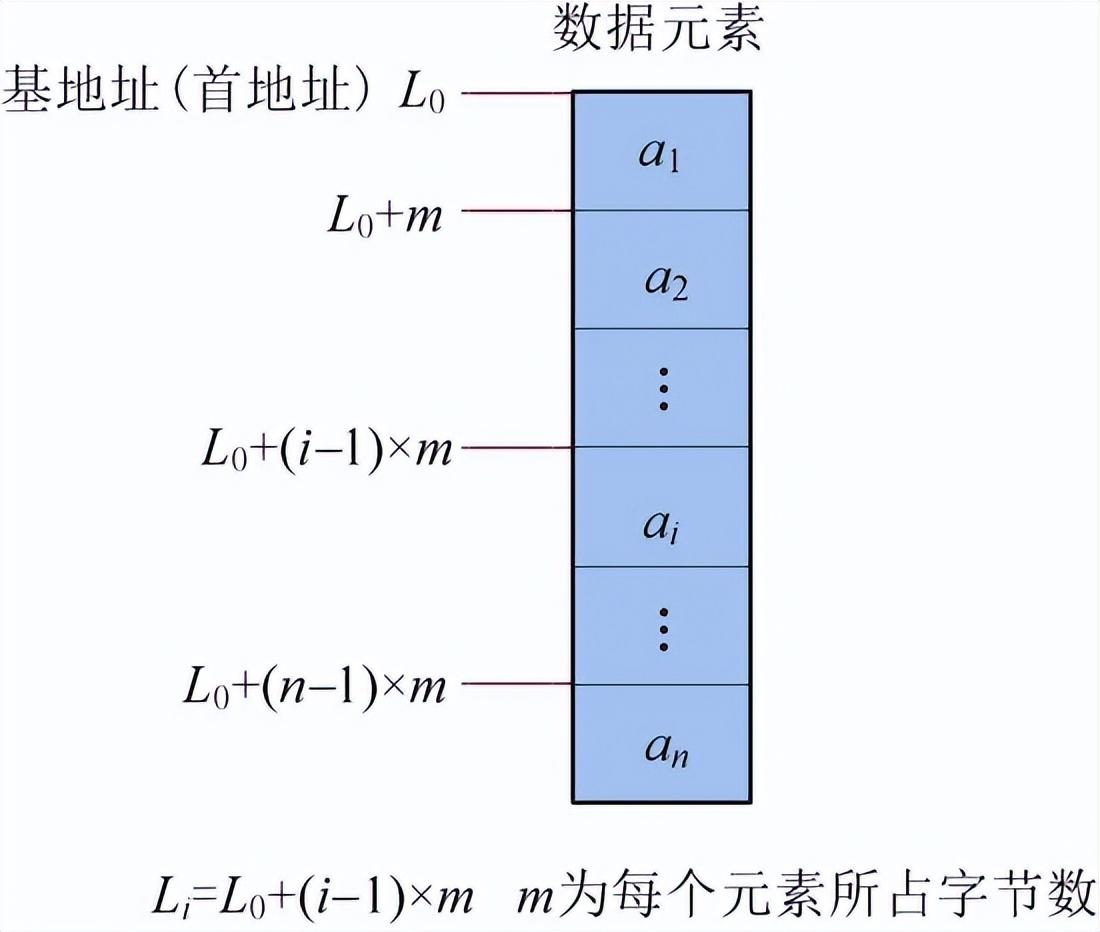
图1-7 顺序存储
(2)链式存储
链式存储是指逻辑上相邻的元素在计算机内的存储位置不一定是相邻的。例如,哥哥张小明因为工作调动去了北京,弟弟仍然在郑州,他们的位置是不相邻的,但是哥哥有弟弟家的地址,很容易可以找到弟弟,就可以说他们是链式存储,如图1-8所示。


图1-8 哥哥有弟弟家地址
链式存储就像一个铁链子,一环扣一环才能连在一起。每个节点除了数据域,还有一个指针域,记录下一个元素的存储地址,如图1-9所示。

图1-9 链式存储
(3)散列存储
散列存储,又称哈希(Hash)存储,由节点的关键码值决定节点的存储地址。用散列函数确定数据元素的存储位置与关键码之间的对应关系,如图1-10所示。
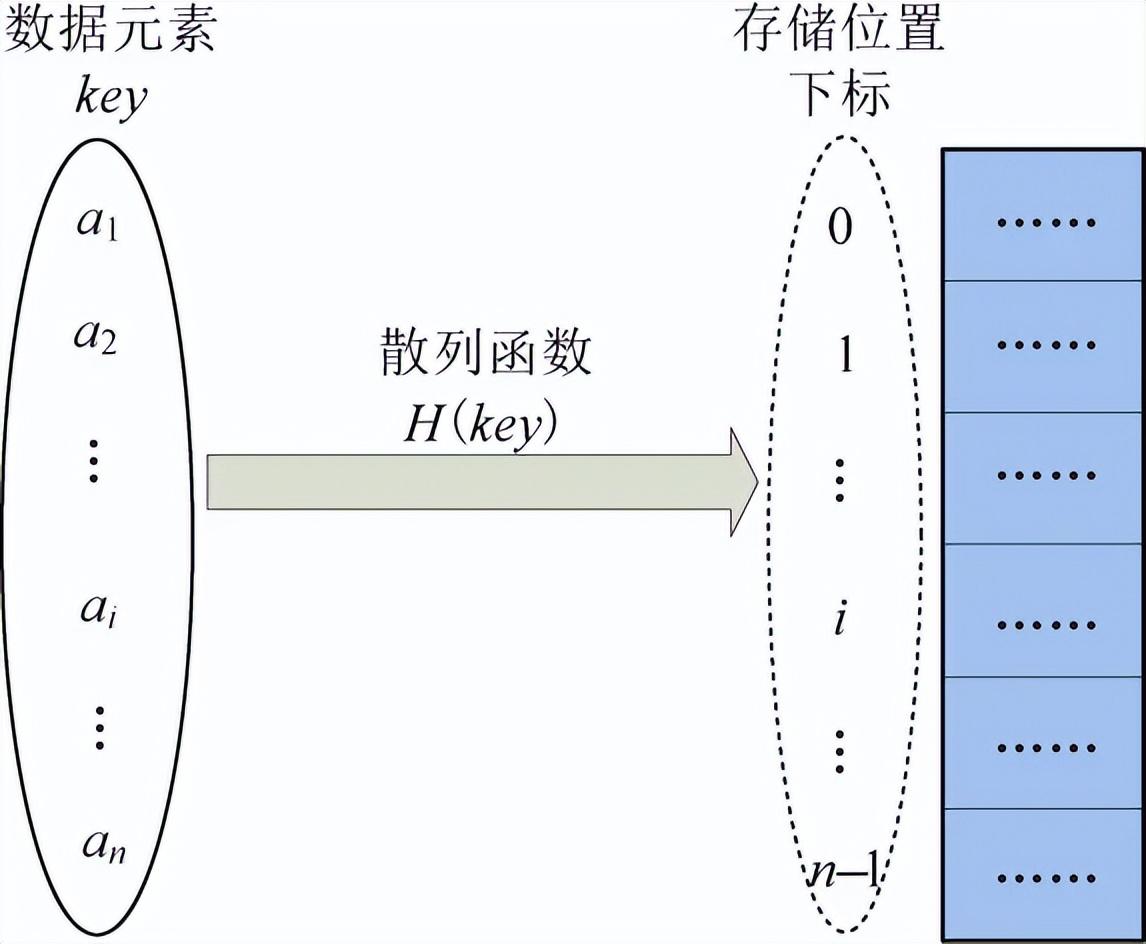
图1-10 散列存储
例如,假设散列表的地址范围为0~9,散列函数为H(key)=key%10。输入关键码序列:(24,10,32,17,41,15,49),构造散列表,如图1-11所示。
24%10=4:存储在下标为4的位置。
10%10=0:存储在下标为0的位置。
32%10=2:存储在下标为2的位置。
17%10=7:存储在下标为7的位置。
41%10=1:存储在下标为1的位置。
15%10=5:存储在下标为5的位置。
49%10=9:存储在下标为9的位置。

图1-11 散列表
散列存储可以通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。如果有冲突,则有多种处理冲突的方法。
(4)索引存储
索引存储是指除建立存储节点信息外,还建立附加的索引表来标识节点的地址。索引表由若干索引项组成。如果每个节点在索引表中都有一个索引项,则该索引表称为稠密索引。若一组节点在索引表中只对应于一个索引项,则该索引表称为稀疏索引。索引项的一般形式是关键字、地址,如图1-12所示。
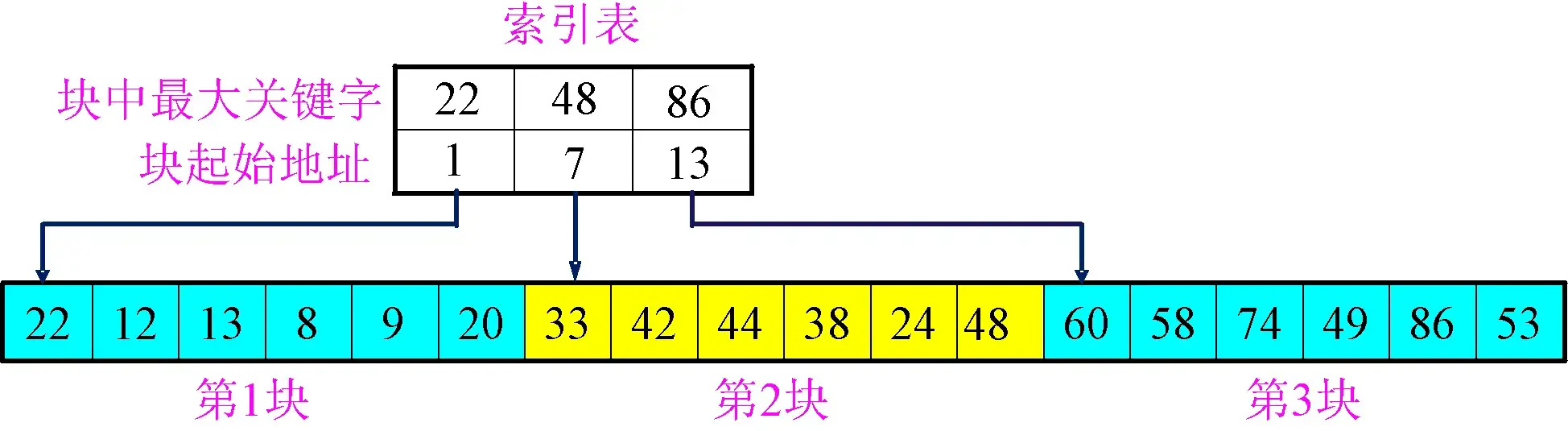
图1-12 索引存储
在搜索引擎中,需要按某些关键字的值来查找记录,为此可以按关键字建立索引,这种索引称为倒排索引。为什么称为倒排索引呢?因为正常情况下,都是由记录来确定属性值的,而这里是根据属性值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。带有倒排索引的文件称为倒排索引文件,又称为倒排文件。倒排文件可以实现快速检索,索引存储是目前搜索引擎最常用的存储方法,如图1-13所示。
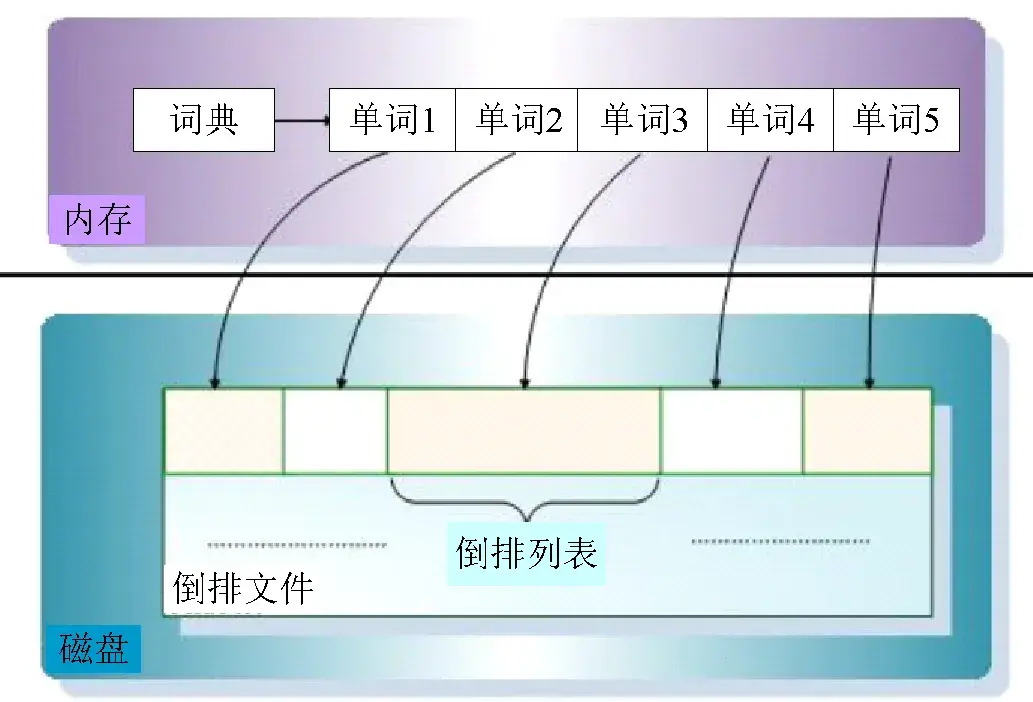
图1-13 倒排索引
7.抽象数据类型
抽象数据类型(Abstract Data Type,ADT)是将数据对象、数据对象之间的关系和数据对象的基本操作封装在一起的一种表达方式,它和工程中的应用是一致的。在工程项目中,开始编程之前,首先列出程序需要完成的功能任务,先不用管具体怎么实现,实现细节在项目后期完成,一开始只是抽象出有哪些基本操作。把这些操作项封装为抽象数据类型,等待后面具体实现这些操作。而其他对象如果想调用这些操作,只需要按照规定好的参数接口调用,并不需要知道具体是怎么实现的,从而实现了数据封装和信息隐藏。在C++中可以用类的声明表示抽象数据类型,用类的实现来实现抽象数据类型的具体操作。
(1)为什么要使用抽象数据类型?
抽象数据类型的主要作用是数据封装和信息隐藏,让实现与使用相分离。数据及其相关操作的结合称为数据封装。对象可以对其他对象隐藏某些操作细节,从而使这些操作不会受到其他对象的影响,这就是信息隐藏。抽象数据类型独立于运算的具体实现,使用户程序只能通过抽象数据类型定义的某些操作来访问其中的数据,实现了信息隐藏。
(2)为什么很多书中没有使用抽象数据类型?
既然抽象数据类型符合工程化需要,可以实现数据封装和信息隐藏,为什么很多数据结构书中的程序并没有使用抽象数据类型呢?因为很多人觉得数据结构难以理解,学习起来非常吃力,因此仅仅将数据结构的基本操作作为重点,把每一个基本操作讲解清楚,使读者学会和掌握数据结构的基本操作,便完成了数据结构书的基本任务。在实际工程中,需要根据实际情况融会贯通,灵活运用,这是后续话题。目前要掌握的就是各种数据结构的基本操作,本书也将基本操作作为重点讲述,并结合实例讲解数据结构的应用。
数据结构和算法相辅相成,密不可分,在学习数据结构之前,首先要了解什么是算法、好算法的衡量标准,以及算法复杂度的计算方法。